There were no contests that I wanted to mention last week, but in the
week before that I forgot to mention
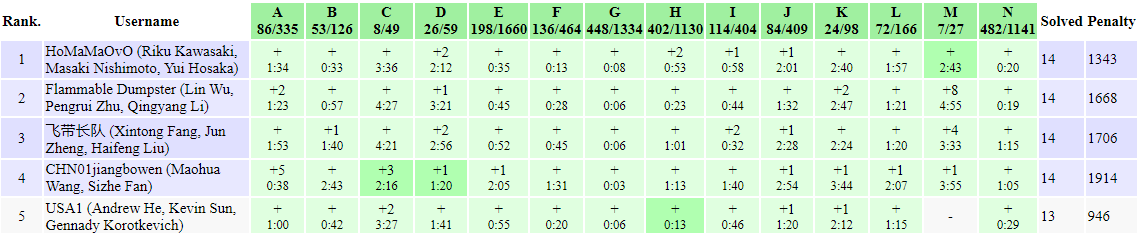
the 3rd Universal Cup Stage 5: Moscow (problems, results, top 5 on the left). Team HoMaMaOvO was the only one to
wrap things up before the last hour, but they still lost out to USA1 because they were a bit slower on the easier
problems: this was one of the relatively rare cases where the ICPC and the AtCoder penalty time formulas place different
teams in the first place. Congratulations to both teams, to team Polish Mafia who were as fast but
had much more incorrect attempts, at to team MIT Isn't Training who were the only remaining team to AK!
What I did not forget to mention were two nice problems.
The
first one came from the EGOI:
There is a sequence of
n bits (each 0 or 1)
ai that is unknown to you.
In addition, there is a permutation
pj of size
n that is known to you.
Your goal is to apply this permutation to this sequence, in other words to construct the
new sequence
bi=
api. Your solution will be invoked as follows.
On the first run, it will read the run number (0) and the permutation
pj, print an integer
w, and exit.
It will then be executed
w more times. On the first of those runs, it will read
the run number (1) and the permutation
pj again, and then it will read
the sequence
ai from left to right, and after reading the
i-th bit,
it has to write the new value for the
i-th bit before reading the next one.
After processing the
n bits, your program must exit. On the second of those runs, it will read
the run number (2) and
pj again, and then read
ai (potentially
modified during the first run) from right to left, and it has to write the new value for the i-th bit before reading the previous one.
On the third of those runs, it goes left to right again, and so on. After the
w-th run is over,
we must have
bi=
api, where
bi is
the final state of the sequence, and
ai is the original state of the sequence.
First, consider the case n=2. If the permutation is an identity permutation, we can just print w=0,
and we're done. The only other case is when the permutation is a swap.
Even in that case, there is actually not that many options for what we can do on the first pass.
First, notice that we must not lose information after the first pass: all 2n
possible sets of values of ai before and after the first pass must be in a one to one
bijective relationship, as otherwise we would have two initial states map to the same state after
the first pass, and since our program is then restarted and we have no other memory except the
current state of ai, we would not be able to distinguish those two initial
states, but the end results for them must be different.
Therefore after reading a0 we have only two options: we either do not change it,
or we change it to the opposite value a0+1 (here and below we use addition modulo 2).
But note that adding 1 on the first pass makes no difference if we have a second pass, since we could just add
1 on reading in the second pass instead. Therefore, without loss of generality we do not change
a0 on the first pass. For a1 we have a few more options since we can
also take a0 into account. More specifically, in each of the two cases
a0=0 and a0=1 we either keep a1 unchanged
or add 1 to it. If we take the same decision in both of those cases, then the whole first pass has
been useless, as we can make the same adjustment on reading in the second pass. Therefore we must take
different decisions. Which one we take in which case is also irrelevant, since they differ by adding a constant,
which can be done in the second pass instead. Therefore once again we can essentially only do one thing:
write a1+a0 as the new value for a1.
By the same argument, on the second pass where we go from right to left we keep a1
unchanged and write a1+a0 as the new value for a0,
and so on. After three passes, we actually obtain the well-known algorithm to swap two values without using
additional memory (note that + and - are the same thing modulo 2):
- a1=a1+a0
- a0=a1-a0
- a1=a1-a0
This means that we have applied the swap as needed. We could only do one thing for n=2, but
this thing turned out to be exactly what we needed when w=3!
Now consider the case of higher n, but when the given permutation is the reverse permutation.
The reverse permutation consists of independent swaps: we need to swap the 0th and the (n-1)-th bits,
the 1st and the (n-2)-th, and so on. Therefore we can simply apply the above trick for
swapping a pair for all of those swaps, and do it in parallel during the same 3 passes, therefore
solving this case with w=3 as well.
We can do the same for any permutation that consists of independent swaps — in other
words for any permutation of order 2. But how to handle the general case? It turns out that any
permutation can be represented as a product of two permutations of order 2! To see how to do it,
we can first notice that it suffices to represent a cycle of arbitrary length as such a product,
as several cycles can be handled independently. We can then consider what happens when we multiply
the following two permutations: the first permutation swaps the 0th and 1st elements, then the 2nd and 3rd
elements, and so on; the second permutation keeps the 0th element in place, swaps the 1st and 2nd elements,
the 3rd and 4th elements, and so on. It is not hard to see that every swap of the second permutation
will swap two elements of different cycles, which means that those cycles will merge, which in turn
means that in the end we will have one big cycle. The nodes along this cycle will not come in the order
0, 1, 2, ..., but it does not matter since we can renumber them arbitrarily to obtain a solution
for any cycle.
This fact can be used to solve the general case with w=6 by applying each of the two
permutations of order 2 using 3 passes. However, we can do one better and achieve w=5
if we notice that the last pass of applying the first permutation and the first pass of applying
the second permutation can be merged into one. In order to see this, notice that we can make
both of those passes go from left to right, and then each of them would find a new value for
a certain bit using the old values of this bit and all previous bits; since our memory is not
erased within one pass, we might as well compute the new value for that bit for the first pass
of the second permutation using the values that would have been computed by the last pass
of the first permutation instead, and write that one directly.
Going from w=5 to the optimal w=3 is a bit more technical, so I will not describe it
in detail. To come up with my own solution for w=3 I relied on a more sophisticated version of
the argument from the solution for n=2. After the second pass, we must leave the bits in such
a state that the final state of each bit depends only on the state of this bit and the previous
bits (since the third pass goes from left to right). And there are actually not too many different things
that we can do during the first pass if we need to be able to leave the bits in such a state after
the second pass. You can also check out alernative approaches in this Codeforces comment, or in the editorial.
The
second problem came from Codeforces:
you are given an empty
n times
m grid (4 <=
n,
m <= 10).
You need to write all integers from 1 to
nm exactly once in the grid.
You will then play the following game on this grid as the second player and need to always win.
The first player takes any cell of the grid for themselves. Then the second player takes any cell that is not taken yet,
but is adjacent (shares a side) to a taken cell, for themselves. Then the first player takes any cell that is not taken yet,
but is adjacent (shares a side) to a taken cell, for themselves, and so on until all cells are taken.
The second player wins if the sum of the numbers of the cells they have in the end is
smaller than
the sum of the numbers of the cells of the first player.
I did not solve this problem, but it turned out that I was on the right track :) On the left you can see the picture I had in my notes during the contest, where I placed 1, 2 and 3, and was trying to prove that if the starting player takes one of them, I can always take the remaining two for myself. On the right you can see the picture from the
excellent editorial, to which I refer you for the actual solution, as I do not have much to add :)
Thanks for reading, and check back for this week's summary!