I have previously posted all the links to the AWTF onsite contests (
day 1,
day 2,
thanks jonathanirvings for the screenshot!), so let us talk about the problems now. I have only solved a few of them, for the remaining ones I have either got the solution from other competitors or read the editorial.
On the first day, the easiest
problem A "Save the monsters", similar to many game problems, required one to consider possible good strategies for both players until you find two that achieve the same score, thus proving that it is the answer. I have made a bug in my initial submit and therefore assumed that I had a logical issue and the approach does not work, but instead it was just a coding mistake.
The key to solving
problem B "Non-Overlapping Swaps" was the idea that if we swap elements in positions 1 and 2, then this swap most likely does not contradict the swaps before and after, so we can use this to divide the entire process into two recursive parts with this swap in the middle. There were still details to figure out as "most likely" does not mean "for sure". This idea did not occur to me unfortunately. I did examine swapping the first two positions as the first move and then doing two independent processes for the two resulting cycles, but it was not clear how to transition from one to the other, and in fact I have found a small counterexample when doing such first move leads to inability to finish in time. I did examine other promising ideas, for example I've noticed that if we have overlapping swaps with a common end, we can always replace them with non-overlapping ones with the same effect, for example swapping positions (a,c) then (b,c) with a<b<c is equivalent to first swapping (b,c) then (a,b). Therefore I was trying to construct some kind of iterative process that gradually removes overlaps.
I've spent most of the time on
problem C "Shrink the Tree". While I could make progress by finding a canonical representation for a tree, I did not have the key idea from the editorial that we should then switch to looking at the problem from the other side: thinking what are the obvious criteria for us to be able to collapse a given forest, and when are they not enough, potentially using a stress test to come up with new criteria. The approach of moving from two sides is similar to problem A, and will actually appear many more times in this problemset. One could also say that thinking from the other side makes an implicit assumption that the problem is beautiful: that the real criteria will be easy to state. Otherwise trying to conjure them up from the air would be much less promising than the "minimal representation for a forest" approach.
Solving
problem D "Welcome to Tokyo!" required doing three things in sequence: applying the trick from Aliens, then looking at the dual problem for a linear program, and finally noticing that solving many instances of that problem with a varying parameter can be done efficiently. My issue was that after applying the trick from Aliens, which I of course considered, we seem to have made the problem more difficult than it was originally, as because of a different party cost we'd have to redo things from scratch every time, and therefore be at least quadratic. Therefore I have discarded this direction as a dead end.
Finally (for day 1), solving
problem E "Sort A[i]-i" required noticing some tricky combinatorial identities. I have not spent much time on this problem because I expected the solution to involve heavy manipulations with generating functions, which I am not very good at. It turns out the generating functions were actually only needed to prove the identities, and therefore could probably be avoided completely. To be honest, I am not sure how feasible it was to find those identities in another way, maybe hos_lyric can share the solving process?
I'd like to give the readers a week to think about second day's
problem A "Hat Puzzle", so I will just share the statement for now:
n people are standing in a row, each with either a red or a blue hat on. Each person can see the hat colors of the people in front of them (with smaller position numbers), but not their own hat color or the hat colors of the people behind them. Each person also knows the total number of red and blue hats. Then, the following process happens in rounds: in one round, every person who can already deduce their hat color, declare that they have done so (they do not declare the color itself). If multiple people can deduce it in the same round, they declare it simultaneously without hearing each other first. In the next round, on the other hand, people can already use the information of who has declared in the previous round to potentally make additional deductions themselves. Which people will eventually declare, and which will still be in the dark about their hat color even after an large number of rounds?
Solving
problem B "The Greatest Two" was once again reliant on "assume the problem is beautiful" or "come up with a bound and then assume/prove it is tight" approach: the key trick was to say that for every number we have a range of possible positions, and that those ranges were more or less independent. Simplifying the problem like this makes the solution a straightforward, if a bit tricky, implementation (it took me ~1.5 hours to implement after having this idea I think), but it was not at all obvious to me that this framework is correct at all, even though it can be proven by induction after the fact, so I just took a leap of faith.
Similarly, the solution for
problem C "Jewel Pairs" seemed to involve two steps where one comes up with a reasonably simple bound and assumes/proves it: first the description of the matching criteria (from the words "Focusing on the form of the mincut" in
the editorial; those words also mean that it might be able to deduce this form analytically instead of going "from the other side", but I did not try doing so myself as I was focusing on other problems), and then the criteria for dealing with the colors 2
f(
c)<=
A-
B.
The key to solving
problem D "Cat Jumps" was finding a way to decompose the overall construction into building blocks that can be combined arbitrarily, so that we can use dynamic programming (or just multiplication) to compute the answer. This is a common theme in many counting problems, but even after reading the editorial I had no idea how to actually come up with the decomposition in this problem. It does not look that we can go from the other side in this case ("What could we reasonably compute with DP for the given constraints?"), and the decomposition itself is too complex to just appear out of nowhere. I did not think much about this problem during the round.
Finally,
problem E "Adjacent Xor Game" was once again solved from the other side: one had to hypothesize or prove that all that matters in the end is how many times each bit is flipped (where going from
y1 to
y2 such that
y1^
y2=
x we count all times a bit is flipped as we count
y1,
y1+1, ...,
y2, not just whether
y1 and
y2 have a difference in a given bit), and we can just get a bound on the answer independently for each bit, and then take a maximum of those bounds. I have spent time building a more direct solution instead (given the lower bound on
y1, how do we find the smallest
y2 for a given
x?), figured out a rule for that with 4 cases, but this road did not seem to lead anywhere. Maybe had I considered replacing going from
y1 to
y2 in one go with processing
y1,
y1+1, ...,
y2 step-by-step, I would have come up with the criteria, but this idea never occurred to me.
Overall, the problems were beautiful and interesting to solve, even if I was feeling quite stuck for long periods of time :) The biggest common theme seems to be that in 5 out of 10 problems (1A, 1C, 2B, 2C, 2E, and maybe also 1D as linear programming duality is the same idea), one had to stop thinking "how can we optimize/improve what we already can" and go from the other side, "what would be the reasonable bounds/criteria when we clearly can't", and then either proving those are tight, or just assuming it. This could be seen as basing the solution on the fact that the problem is beautiful, or at the very least on the fact that it is solvalbe for the given constraints. So one takeaway is that I should try this solving approach more often.
I'm sorry for a long brain dump, feel free to tell me that what I'm writing makes no sense at all :)
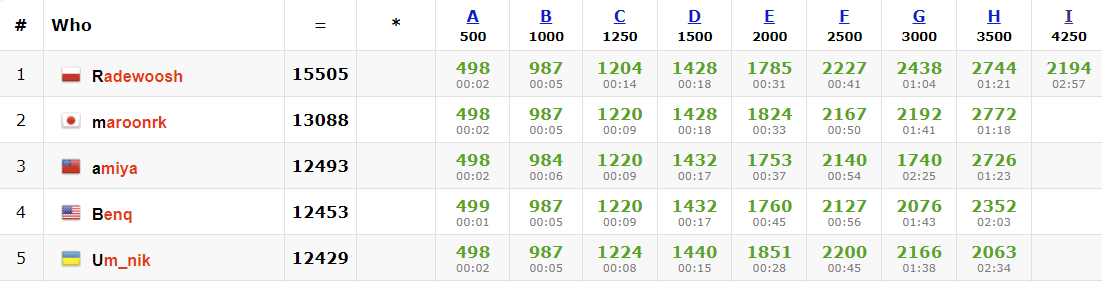
The 2nd Universal Cup Stage 2: SPb also took place over the weekend (
problems,
results, top 5 on the left). This season follows the highly successful
debut season of the Universal Cup, which has more or less taken Open Cup's space as the main team competition outside of the ICPC system. As I understand,
Stage 1 of the 2nd Universal Cup was declared unrated because of the server problems, so this was the actual first stage.
On the surface, it might have seemed that making last season's winner USA1 even stronger would be impossible, but they have found a way, demolishing the field in just over three hours with Gennady on the team. Well done!
It would be nice to gather Petr Team again to participate, but given that the number of stages in a year is ~2x that of the Open Cup, with a stage is happening almost every weekend, the time commitment required to feel a real part of the proceedings would be way too big. We should try to do a one-off round some time, though :)
Codeforces Round 896 wrapped up the week (
problems,
results, top 5 on the left,
analysis,
discussion). Quite fittingly, the first two places in the round went to the problemsetter (
well, well) and the winner of AWTF. Congratulations to both!
In
the last week's summary, I have mentioned
a Codeforces problem: you are given an array of at most 10000 integers, each between 0 and 2
60. In one operation, you split the array in the middle into two parts, compute the bitwise xor of each part, and discard the part where the bitwise xor is smaller. In case they are equal, you may discard either part. After doing this operation several times, you have just one number remaining. Which positions in the initial array could this number correspond to?
The first observation, which taking bitwise xors of two parts points to, is to notice that the bitwise xor of the bitwise xors of the two parts is equal to the bitwise xor of the entire array. Therefore if the bitwise xor of the first part is x, and the bitwise xor of the entire array is s, then the bitwise xor of the other part can simply be found as s^x. And when comparing x and s^x, they will differ in those bits where s has a 1 bit, therefore we need to look at the highest 1 bit of s, and we will always choose such part that x has a 1 bit in that position. This condition is both necessary and sufficient: any part which has a 1 bit in that position will be chosen.
The fact that only the highest 1 bit matters allows to speed up the straightforward dynamic programming from O(n3) to O(n2), because we can handle multiple transitions at the same time. The dynamic programming will compute for each of the O(n2) subsegments whether we can reach it. For O(n3) complexity, for every reachable state we can simply iterate over all ways to move the left boundary while keeping the right boundary constant, or vice versa, and check if a move is possible (by comparing x and s^x).
However, we can notice that doing the transitions that try moving from (l,r) to (l,r-2), (l,r-3), ... and the transitions that try moving from (l,r-1) to (l,r-2), (l,r-3), ... have many things in common. In fact, if (l,r) and (l,r-1) have the same highest 1 bit in their bitwise xor, then those transitions are either possible or not possible at the same time.
This hints at what should we be computing in the O(n2) dynamic programming: for every segment (l,r) we will compute the set of possible highest 1 bits (represented as a bitmask) of all reachable containing segments with the same left boundary (l,r1) where r1>r, and the same for the containing segments with the same right boundary. To compute this number for (l,r) we can take the same number for (l,r+1) and update it with the highest 1 bit of the bitwise xor of the segment (l,r+1), if it is reachable. And knowing this bitmask allows to check if this segment is reachable by simply testing if this bitmask has a non-zero bitwise and with the bitwise xor of this segment.
Another way of putting the same idea is to say that we're introducing intermediate states into our dynamic programming to aid reuse: instead of going from a reachable segment to its prefix or suffix directly, we now first go from a reachable segment to a (segment, highest 1 bit, decision whether we will change left or right boundary) tuple, which allows to add transitions between those tuples, and transitions from those tuples back to segments, in such a way that we have O(1) transitions per tuple instead of having O(n) transitions per segment. This would mean going from O(n2) states and O(n3) transitions to O(n2*#bits) states and O(n2*#bits) transitions, but then using bitmasks helps get rid of the #bits factor.
Thanks for reading, and check back next week!


 In continuing another great Open Cup tradition, Universal Cup is holding a Prime Contest this and next week. Given the higher amount of Universal Cup rounds, the Prime Contest appears practially infinite with problem numbers going up to 167, and nevertheless 36 out of 39 problems have already been solved, and even more amazingly 26 of those were solved by the same team! There are still 5 days left and 3 problems have not yet been solved, so maybe this is your chance — but remember that those problems are not for the faint-hearted :) You need an Universal Cup login to participate, and I believe you can get one via the registration form.
In continuing another great Open Cup tradition, Universal Cup is holding a Prime Contest this and next week. Given the higher amount of Universal Cup rounds, the Prime Contest appears practially infinite with problem numbers going up to 167, and nevertheless 36 out of 39 problems have already been solved, and even more amazingly 26 of those were solved by the same team! There are still 5 days left and 3 problems have not yet been solved, so maybe this is your chance — but remember that those problems are not for the faint-hearted :) You need an Universal Cup login to participate, and I believe you can get one via the registration form. Codeforces Good Bye 2023 wrapped up the competitive year (problems, results, top 5 on the left). The round was not received well (1, 2, 3), but nevertheless congratulations to ksun48 on being the only one to solve everything and therefore getting a clear first place!
Codeforces Good Bye 2023 wrapped up the competitive year (problems, results, top 5 on the left). The round was not received well (1, 2, 3), but nevertheless congratulations to ksun48 on being the only one to solve everything and therefore getting a clear first place!















.jpg)