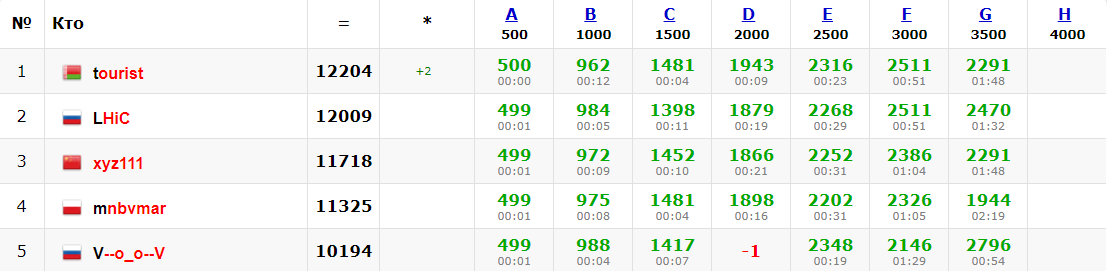
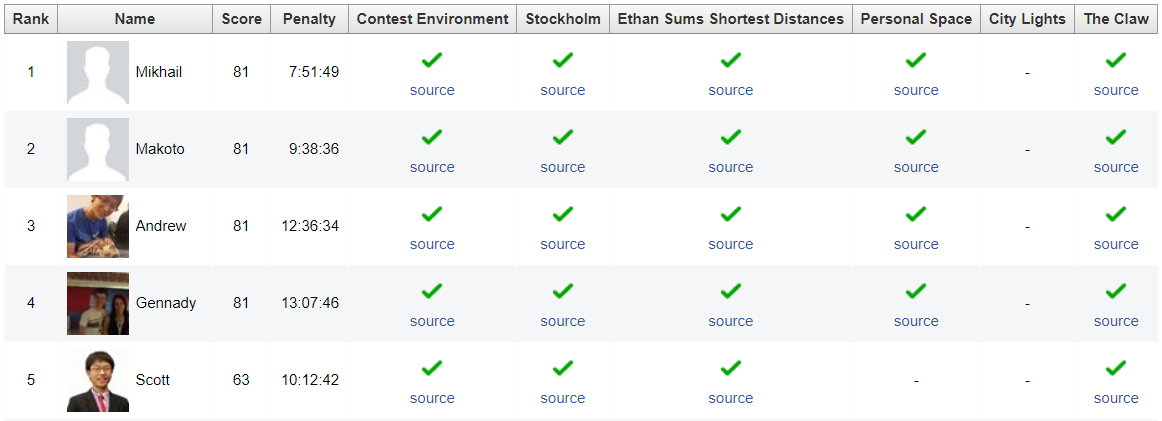
AtCoder held its last contest of the year (and thus the last contest included in the onsite finals selection) on Saturday, the Grand Contest 030 (problems, results, top 5 on the left, my screencast, analysis, onsite finals selection standings, top 8 below on the right). Reading all problems really paid off in this round, as different contestants found different problems the hardest. For me problems B and C were the most difficult — in fact, I could not come up with a solution for any of them. It seems that the top two contestants cospleermusora and tourist had a similar story with problem C, but since it was worth less than problems E and F they ended up on top of the contestants with a different set of 5 problems solved. Congratulations to cospleermusora on the win!
 Here is that problem C that was obvious for some and impossible to get for others: you are given a number k which is at most 1000. You need to come up with any nxn toroidal grid (the first row is adjacent to the last row, and the first column is adjacent to the last column), where you choose the number n but it must be at most 500, such that each cell of the grid is colored with one of the k colors, each color is used at least once, and for all pairs of colors i and j all cells with color i must have the same number of neighbors with color j. Can you see a way?
Here is that problem C that was obvious for some and impossible to get for others: you are given a number k which is at most 1000. You need to come up with any nxn toroidal grid (the first row is adjacent to the last row, and the first column is adjacent to the last column), where you choose the number n but it must be at most 500, such that each cell of the grid is colored with one of the k colors, each color is used at least once, and for all pairs of colors i and j all cells with color i must have the same number of neighbors with color j. Can you see a way?
 Codeforces held the Good Bye 2018 round on Sunday (problems, results, top 5 on the left, my screencast, analysis). tourist had one more great performance, going through the problems in order and finishing all of them more than 30 minutes faster than the only other contestant to solve everything, MakeRussiaGreatAgain. Congratulations to both!
Codeforces held the Good Bye 2018 round on Sunday (problems, results, top 5 on the left, my screencast, analysis). tourist had one more great performance, going through the problems in order and finishing all of them more than 30 minutes faster than the only other contestant to solve everything, MakeRussiaGreatAgain. Congratulations to both!
My round was going pretty well right up to the point when I googled the main idea of the solution for problem G, but then made a bug in the implementation (I forgot that the square roots are always returned modulo n, and not modulo the "remaining" number that I still need to factorize), and instead of looking for it I assumed there's a problem with BigInteger.isProbablePrime in Codeforces and tried to work around it for quite some time. I've found this post with no answers and the post linked from it, and the fact that some of my submissions were getting "Denial of judgement" strongly supported the isProbablePrime failure theory.
Problem H had a pretty convoluted statement which boiled down to: there is a pile with n<=200000 stones, and two players are playing Nim with a fixed set of possible moves a1, a2, ..., ak: in each turn a player can take a number of stones that is equal to one of the ai, and the player who can't make a move loses. Your goal is to find the nimbers for all values of n between 1 and 200000.
I've tried to solve this problem at the end of the contest, but my mental state after fighting with G for an hour was not ideal :) I realized that I needed to speed up the standard quadratic approach 64 times using bitsets, but could not find a good way to do that. Can you see a way?
Thanks for reading, and check back [hopefully] tomorrow for my take on the best problems of 2018!

My round was going pretty well right up to the point when I googled the main idea of the solution for problem G, but then made a bug in the implementation (I forgot that the square roots are always returned modulo n, and not modulo the "remaining" number that I still need to factorize), and instead of looking for it I assumed there's a problem with BigInteger.isProbablePrime in Codeforces and tried to work around it for quite some time. I've found this post with no answers and the post linked from it, and the fact that some of my submissions were getting "Denial of judgement" strongly supported the isProbablePrime failure theory.
Problem H had a pretty convoluted statement which boiled down to: there is a pile with n<=200000 stones, and two players are playing Nim with a fixed set of possible moves a1, a2, ..., ak: in each turn a player can take a number of stones that is equal to one of the ai, and the player who can't make a move loses. Your goal is to find the nimbers for all values of n between 1 and 200000.
I've tried to solve this problem at the end of the contest, but my mental state after fighting with G for an hour was not ideal :) I realized that I needed to speed up the standard quadratic approach 64 times using bitsets, but could not find a good way to do that. Can you see a way?
Thanks for reading, and check back [hopefully] tomorrow for my take on the best problems of 2018!